Log Regex Markup
The Log Regex Markup engine is a unique and highly practical feature of IO Ninja, designed to enhance data log analysis with intuitive visual aids. This engine uses user-defined regular expressions to automatically—and instantly!—highlight data patterns or insert packet delimiters. It’s powered by Google RE2, one of the world’s fastest and most reliable regular expression libraries.
How to Add Regex Markup
Click “Edit” and then “Log Regex Markup” from the toolbar.
In the Log Regex Markup window, check the “Enable regex markup” checkbox.
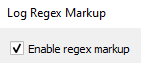
Enter a regex, (see “Syntax” section below for details).
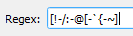
Adjust markup settings as needed and press “OK”.
Check the log to see your regex markup in action.
Syntax
Since the regex markup engine is powered by Google RE2, it supports all the features of RE2. For a full syntax specification, refer to the official RE2 wiki page. If you’re looking for a quick start, check out the quick cheat sheet below—it’s more than enough to get you going.
Construct |
Description |
Example |
|---|---|---|
|
Any character |
|
|
Alternative |
|
|
Character class |
|
|
Negated character class (e.g., |
|
|
ASCII Character class |
|
|
Negated ASCII Character class |
|
|
Group a sub-expression |
|
|
Preceding element is optional |
|
|
Preceding element is optional (non-greedy) |
|
|
Preceding element is repeated zero or more times |
|
|
Preceding element is repeated zero or more times (non-greedy) |
|
|
Preceding element is repeated one or more times |
|
|
Preceding element is repeated one or more times (non-greedy) |
|
|
Preceding element is repeated exactly |
|
|
Preceding element is repeated at least |
|
|
Preceding element is repeated at least |
|
|
Preceding element is repeated from |
|
|
Preceding element is repeated from |
|
Anchor |
Description |
|---|---|
|
Match at the beginning of line (or beginning of text) |
|
Match at the end of line (or end of text) |
|
Match at the beginning of text |
|
Match at the end of text |
|
Match at a word boundary |
|
Match if not at a word boundary |
Special character |
Description |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Character code |
Description |
Example |
|---|---|---|
|
Character specified by three octal digits |
|
|
Character specified by two hexadecimal digits |
|
|
Character specified by hexadecimal digits |
|
Perl character class |
Description |
Expands to |
|---|---|---|
|
Decimal digits |
|
|
Not decimal digits |
|
|
Word characters |
|
|
Not word characters |
|
|
Whitespace |
|
|
Not whitespace |
|
ASCII character class |
Description |
Expands to |
|---|---|---|
|
Alphanumeric |
|
|
Alphabetic |
|
|
ASCII |
|
|
Blank |
|
|
Control |
|
|
Decimal digits |
|
|
Graphical |
|
|
Lower case letters |
|
|
Printable |
|
|
Punctuation |
|
|
Whitespace |
|
|
Upper case letters |
|
|
Word characters |
|
|
Hexadecimal digits |
|