Writing a Protocol Analyzer Plugin
In this tutorial, we will show you how to write a protocol analyzer for our tutorial protocol TutoProto.
TutoProto Analyzer Project
Start the IO Ninja IDE, click the menu File/New Project, choose the category IO Ninja and the project type Plugin Project. On the next screen, set the plugin type to Protocol Analyzer, enter TutoProto as the project name, choose the location for your plugin, and hit Next.
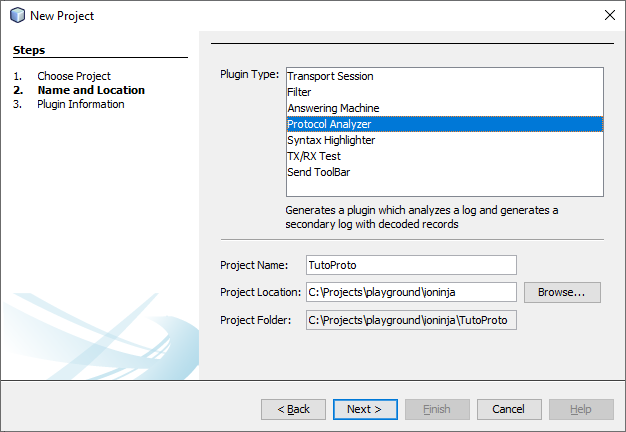
On the next screen, enter appropriate informational strings and punch TutoProto in as a layer prefix – so that all class and function names will be named appropriately.
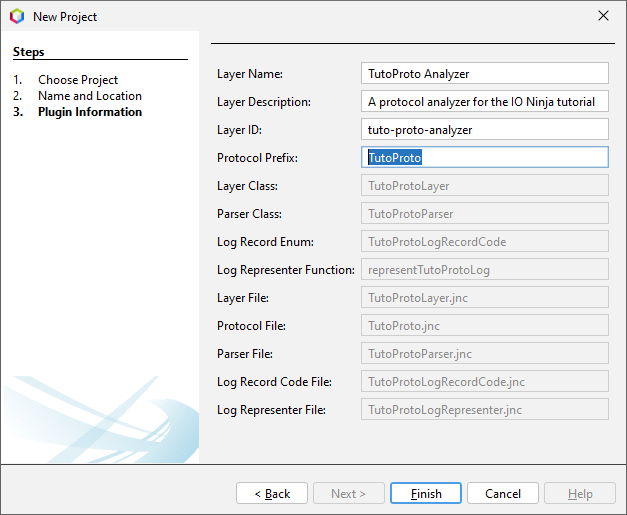
Hit Finish, and the skeleton for a new protocol analyzer will be generated.
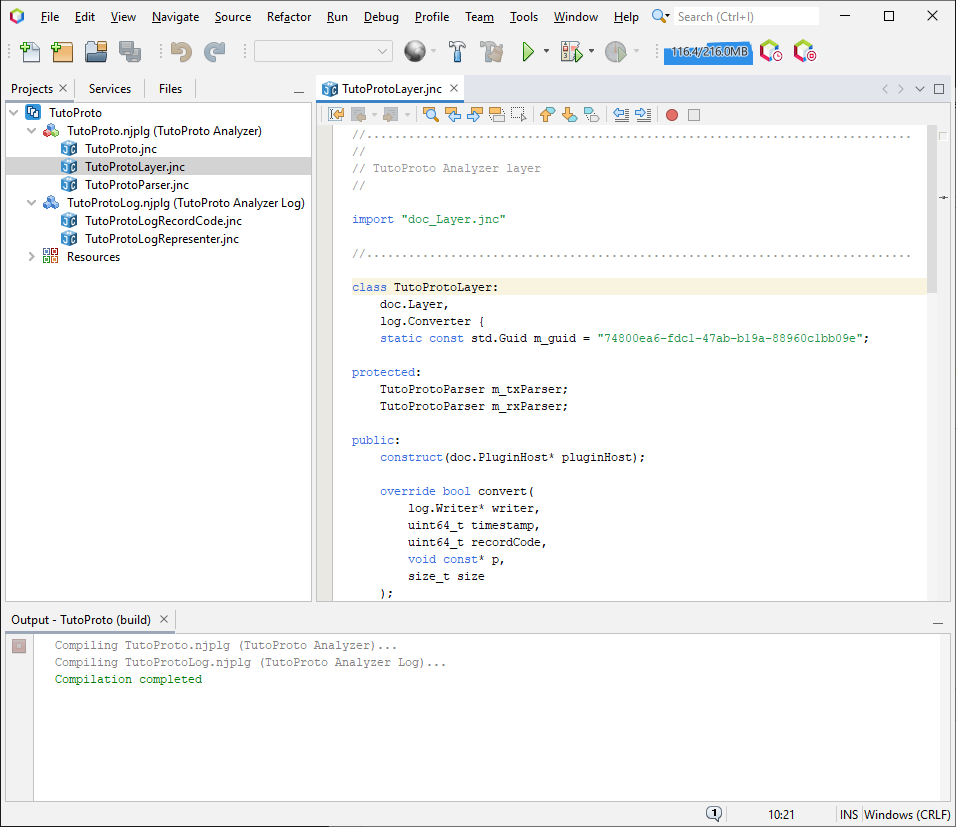
The wizard will actually generate two plugins. One is a layer plugin that will parse the original log, augment it with decoded protocol messages, and write it as a secondary log. The second plugin is a log representer plugin that will generate a visual representation for the newly added decoded protocol messages.
The files generated by the wizard for our project are:
| File | Description |
|---|---|
TutoProto.njplg |
Plugin file for the analyzer layer |
TutoProto.jnc |
Protocol structures and constants |
TutoProtoLayer.jnc |
Analyzer layer plugin class |
TutoProtoParser.jnc |
Stream parser class |
TutoProtoLog.njplg |
Plugin file for the log representer |
TutoProtoLogRecordCode.jnc |
Plugin-specific log record codes and structures |
TutoProtoLogRepresenter.jnc |
Representer of the plugin-specific log record codes |
images/ |
Plugin icons and other images |
Modifications for TutoProto
The wizard generates a dynamic layout-based protocol analyzer for a simple made-up binary protocol. That protocol is not TutoProto, but it is similar in concept – simple but encompassing many concepts of the real-world protocols.
In any case, we’ll need to update the generated code for TutoProto. We have to do the following:
Add protocol structures & constants to the protocol file (
TutoProto.jnc)Modify the packet layout function (
layoutTutoProtoinsideTutoProto.jnc) according to our protocol specificationThis function will be used by:
- Stream parser class (
TutoProtoParser) to buffer the correct number of bytes from TX and RX streams before writing them to the log - Log representer function (
representTutoProtoLog) to generate visual representation of the buffered packets in the log - Packet template engine (if the user wants to prepare test packets using a property grid from the “Transmit” pane)
- Stream parser class (
Modify the packet digest function (
getTutoProtoDigestinsideTutoProto.jnc)This function is indirectly called by the log representer when the packet log record is collapsed and displayed as a single line (instead of a tree view when the packet record is expanded).
The rest of the generated code could be kept intact.
Note
For other protocols, the buffering logic might also need some adjustments.
A wizard-generated parser looks for STX (code 0x02) before starting to lay out and buffer a packet. Packets in TutoProto also start with STX – so we don’t have to change anything here.
However if packets in your protocol start with a character other than STX (or if they don’t have a fixed preamble at all), then necessary adjustments must be made in the stream parser class.
That’s the roadmap; let’s get to it.
Copy-pasting TutoProto definitions into TutoProto.jnc is pretty straightforward. Further modifications, however, may need some explanation.
Layout Function
A layout function receives a pointer to a jnc.DynamicLayout object and populates it with discovered data fields using dyfield (i.e., dynamic field) declarations.
Within this function, you can access any previously declared dyfield normally, just like you do with local variables. And, of course, you can implement any logic using the if/else/switch branching and/or loops, thus building structures of arbitrary complexity.
A minimal layout function for TutoProto could look like this:
async void layoutTutoProto(jnc.DynamicLayout* layout) { dylayout (layout) { dyfield TutoProtoHdr hdr; if (hdr.m_flags & TutoProtoFlags.Error) dyfield TutoProtoError error; else switch (hdr.m_command) { case TutoProtoCommand.GetVersion: if (hdr.m_flags & TutoProtoFlags.Reply) dyfield TutoProtoVersion version; break; case TutoProtoCommand.Read: if (hdr.m_flags & TutoProtoFlags.Reply) dyfield char data[hdr.m_size - sizeof(TutoProtoHdr)]; else dyfield TutoProtoRange read; break; case TutoProtoCommand.Write: if (hdr.m_flags & TutoProtoFlags.Reply) break; dyfield TutoProtoRange write; dyfield char data[write.m_length]; break; } dyfield bigendian uint16_t crc; } }
Note the async modifier of the layout function. This converts a regular function into a coroutine thus making it possible to pause and resume its execution when necessary.
Note
Why is the layout function a coroutine?
Many transports (Serial, TCP, SSL, etc) don’t guarantee delivery of a packet as a whole. Even when the transmitting side issues a single write/send request, the data could be transferred and delivered as a series of smaller blocks. Therefore, we could end up in a situation when we received and parsed part of the packet only to discover that we haven’t received the whole packet yet – thus, we have to pause and wait for the missing bytes. After we receive those bytes, we can pick up exactly where we left off, without doing the redundant work of parsing the packet from the beginning.
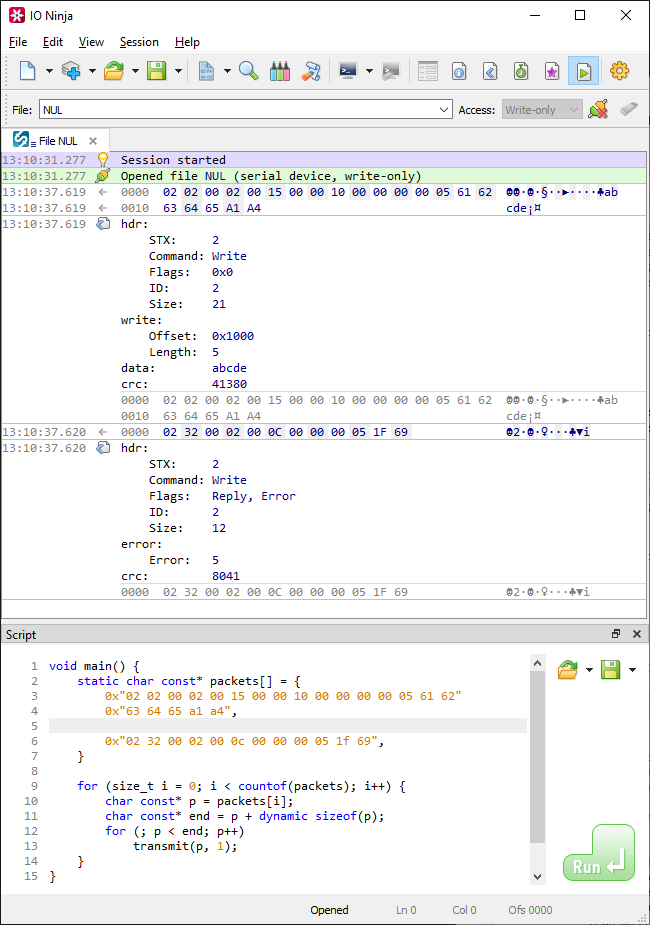
This minimal example above will work and properly reassemble, buffer, and parse our TutoProto protocol packets (note that on the screenshot below packets are transmitted one byte at a time):
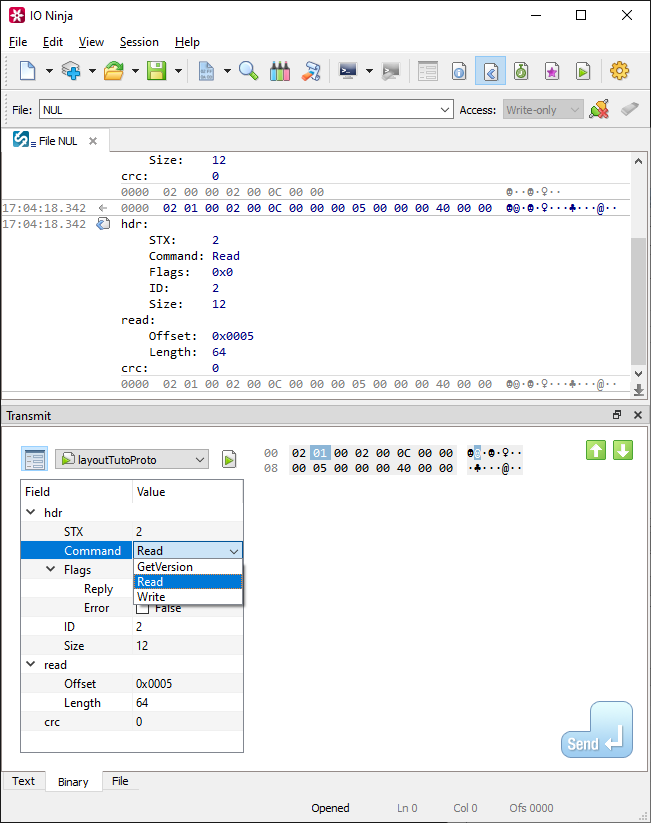
If you add the [ packetTemplate ] attribute to this function, it will also get registered as a packet template – now you will be able to conveniently fill test TutoProto packets via a property grid of the “Transmit” pane:
Folds
Even for a protocol as simple as TutoProto the fully expanded packet representation takes quite a lot of screen space – that makes it hard to follow the conversation between the nodes. Often times, it’s much better to only show brief information for each packet by default, and only expand all details when and if a user explicitly requests that.
One possible approach here is via the foldable log records. When a log record code has the log.RecordCodeFlags.Foldable flag set, the logging engine can represent it differently – depending on the 32-bit foldFlags integer. Essentially, you have 32 layers of folding at your disposal – that’s more than enough for all real-world protocols.
The generated log record codes already include log.RecordCodeFlags.Foldable, so all you have to do is to properly mark folding points in the layout function. In order to do so, add the foldFlag attribute to a struct field or a group. For example, adding this:
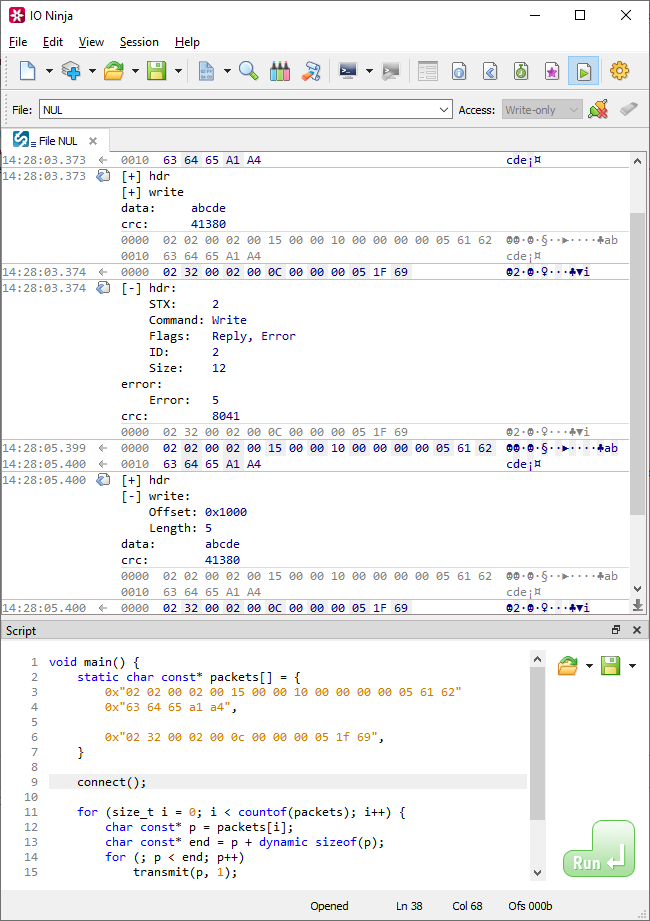
... [ foldFlag = 1 ] dyfield TutoProtoHdr hdr; ... [ foldFlag = 2 ] dyfield TutoProtoRange read; ... [ foldFlag = 2 ] dyfield TutoProtoRange write;
will make the header, read, and write structures collapsed by default; clicking on the [+] button will expand them:
Note
When assigning fold bits, be sure to assign different bits to structures that can be seen at the same time; structres that are never seen together could share the same fold bit (e.g., read and write can both use fold flag 2 because they are mutually exclusive).
Digest Function
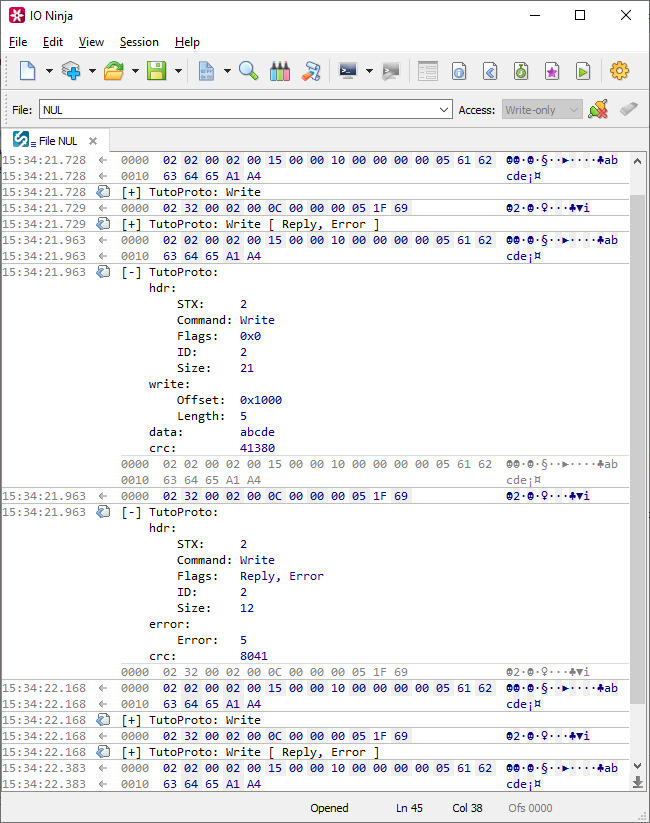
Making individual portions of a packet collapsible was a step in the right direction. Probably, even better would be to make the whole packet collapsed and shown with a short digest. When a user needs more information, he can click on a [+] to show all the intricate details.
Let’s group all the packet dyfields into one root group and assign the following attributes to it:
dylayout (layout) { [ displayName = "TutoProto", foldFlag = 1, digestFunc = getTutoProtoDigest ] dyfield { dyfield TutoProtoHdr hdr; ... }
Now, we have to write the function getTutoProtoDigest that will generate a string with some basic information about the packet – this string will be shown when the whole packet is collapsed.
string_t getTutoProtoDigest( void const* p, size_t size ) { TutoProtoHdr const* hdr = (TutoProtoHdr const*)p; std.StringBuilder digest = typeof(TutoProtoCommand).getValueString(hdr.m_command); if (hdr.m_flags) digest += $" [ %1 ]"(typeof(TutoProtoFlags).getValueString(hdr.m_flags)); return digest.detachString(); }
Note
One approach to writing a digest function is to reuse the very same dynamic layout approach we utilized in the layout function above. A digest function, however, doesn’t need to be async (it always receives a complete packet, so there’s no need to pause-and-resume).
Also, a digest function can be simpler than the corresponding layout function because the former doesn’t have to analyze the packet structure in-depth. Instead, it only needs to extract just enough information for a digest string.
Visual Attributes
Finally, let’s augment the dynamic fields with appropriate visual attributes. Besides making the output of our protocol analyzer pleasing to the eye, it also provides important visual clues for how the packet fields map to raw bytes.
| Attribute | Description |
|---|---|
ungroup |
Don’t create a subgroup for this struct or group – i.e., add all sub-fields at the same level |
payload |
Display this field as a binary payload blob (e.g., as a hex-view or plain text depending on the log binary data settings) |
displayName |
Specify the visible name for a field |
formatSpec |
Specify the printf format specifier for a field (e.g., 0x%04X to display it as a hexadecimal integer) |
backColor |
Specify the background color for a field. Applies both to the property grid and the hex-editor. |
The following dynamic field attributes could be necessary if we also register our layout function as a packet template via the [ packetTemplate ] attribute. This way, the layout function will be shared between log and the packet template engine, so we have to take some extra steps to ensure it looks good in both places.
| Attribute | Description |
|---|---|
root |
Mark the root group of your layout function with this attribute. Root packet groups help us make the whole packet foldable. Inside the packet template property grid, however, we don’t normally want this extra folding layer. |
displayNameAttr |
Specify ANSI escape code(s) of visual attributes to apply to the display name in the log. This attribute is ignored in the packet template property grid. |
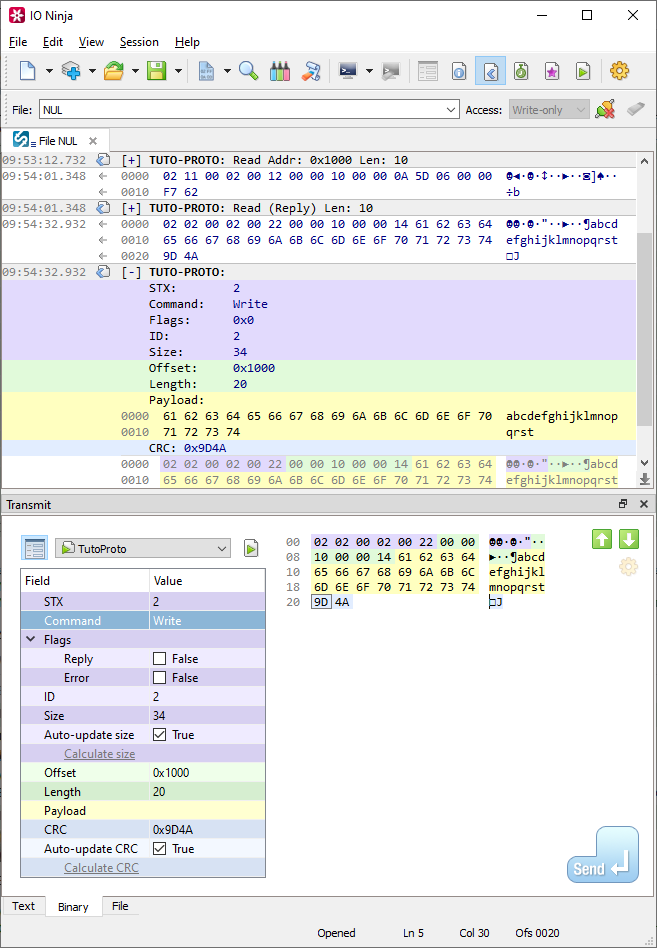
Depending on the visual attributes we choose, the final version of our protocol analyzer could look something like this:
Download
Full sources of the TutoProto analyzer plugin can be downloaded via the links below:
| File | URL |
|---|---|
TutoProto source (.7z) |
https://ioninja.com/downloads/samples/TutoProto.7z |
TutoProto source (.tar.xz) |
https://ioninja.com/downloads/samples/TutoProto.tar.xz |