
Walking Your Log


Questions similar to this one often pop up both on the forum and in support emails:

A user wants to analyze captured data using their own scripts. A very reasonable request. Can this be done? Absolutely! IO Ninja is scriptable in Jancy and was designed to be extensible with layers (protocol analyzers, filters, converters, etc.) All IO Ninja plugins you use are actually Jancy scripts – open source and available for you to inspect or modify:
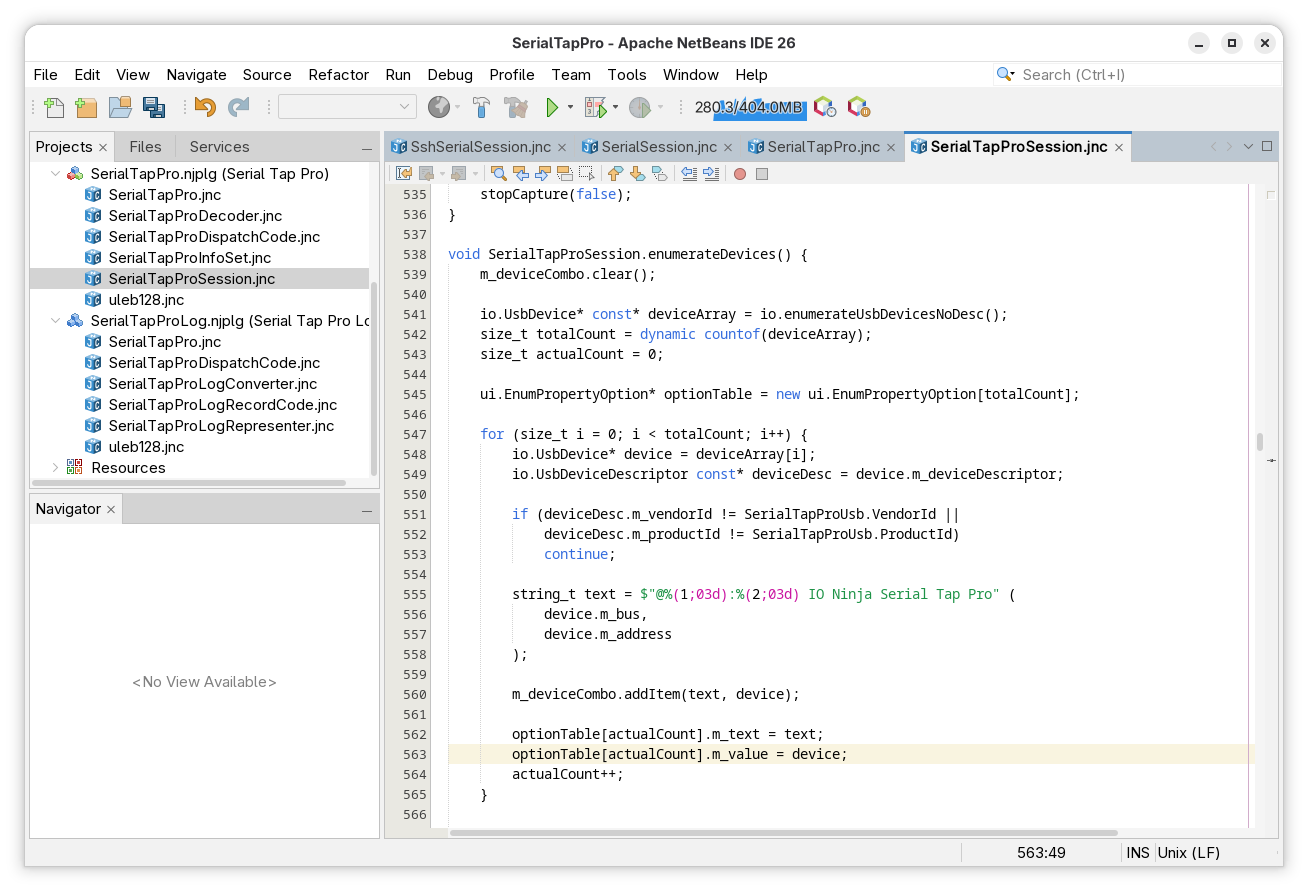
However, many users would rather use languages and tools they already know and are familiar with. Something like Python. This blog post will show how to do exactly that.
Overview of Logging in IO Ninja
What you see in the main view of IO Ninja is a visual representation of a log record file (*.njlog):
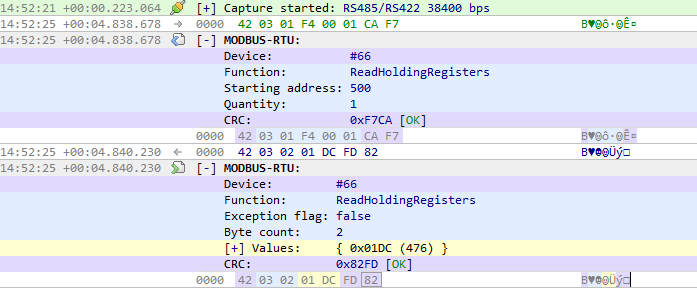
This .njlog file is always present – even for temporary sessions (for such sessions, .njlog gets auto-deleted when the IO Ninja process exits.)
.njlog file is extremely simple. It's a binary file that starts with a header followed by a sequence of log records all the way down. Each record contains a timestamp, a code to identify the type of record (e.g., incoming data, line change notification, connection error, etc.), and associated data (the semantics of which depend on the particular record code). That's it!When an IO Ninja session is active, its scripts add records to the session .njlog for every event worth showing to you. Then the IO Ninja log engine runs a so-called representer to convert binary record blobs into a human-readable representation you see on the screen. Pretty simple so far, right?
Things get a bit more interesting when we throw protocol analyzers into the mix. Obviously, we do not want to irreversibly damage the original log by replacing raw data with (or even simply adding) decoded packets. What if we decide to re-parse everything using a different protocol analyzer? Or the same one but with different parameters? We should be able to return to the original raw log at any time, period.
As such, when we add one or more converting layers, the original record file is kept intact, and a secondary .njlog is created to hold the results of the conversion pipeline. This secondary record file is what we see on the screen. When a session wants to write new records to the log, they actually end up in the original .njlog file (and then propagate all the way through the pipeline and into the secondary .njlog).
When saving the log of a layered session into a file, we can select which .njlog to use:
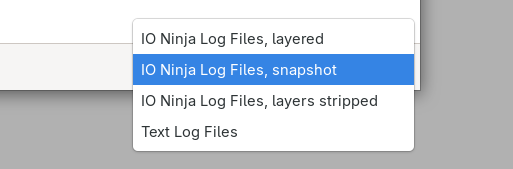
.njlog, choose one of these two.The resume for our brief overview:
- Every event you see in the IO Ninja main view is stored in a record (
.njlog) file - The
.njlogfile format is trivial - When converter layers are involved, there is an extra record file that stores the decoded packets (the original
.njlogstays intact)
And the logical conclusion here is:
.njlog file and work with it using a language of your choice!We'll use Python – it's hugely popular and well-suited for handling binary data. With some adjustments, all the concepts below can be applied to other scripting languages as well.
Decoding .njlog with Python
As mentioned above, IO Ninja scripts are all open source and distributed with every installation package. In particular, declarations relevant to the log record file format reside in <IONINJA_DIR>/scripts/api/log_RecordFile.jnc
This file is tiny (~50 lines long), and here's the gist of it:
struct RecordFileHdr {
uint32_t m_signature; // log:
uint32_t m_version;
uint64_t m_recordCount;
uint64_t m_totalRecordSize;
uint32_t m_lastRecordSize;
uint32_t m_recordOffset : 24;
uint32_t m_auxRepresenterCount : 8;
std.Guid m_representerGuid;
// followed by std.Guid[m_auxRepresenterCount]
// followed by aux headers (such as layered log metadata)
// followed by log records at m_recordOffset
}
struct Record {
uint32_t m_signature; // \nrc:
uint32_t m_dataSize;
uint64_t m_code;
uint64_t m_timestamp; // windows filetime
// followed by record data (if any)
}Jancy declarations for .njlog file-related structures
To move this to Python, we'll use the good old ctypes package – it provides a one-to-one mapping for nearly all features of C-like structures. Here's how the Jancy declarations above would look in the Python world:
import ctypes as C
class RecordFileHdr(C.LittleEndianStructure):
_fields_ = [
("signature", C.c_uint32),
("version", C.c_uint32),
("record_count", C.c_uint64),
("total_record_size", C.c_uint64),
("last_record_size", C.c_uint32),
("record_offset", C.c_uint32, 24),
("aux_representer_count", C.c_uint32, 8),
("representer_guid", C.c_uint8 * 16),
]
SIGNATURE = C.c_uint32.from_buffer_copy(b'log:').value
class Record(C.LittleEndianStructure):
_fields_ = [
("signature", C.c_uint32),
("data_size", C.c_uint32),
("code", C.c_uint64),
("timestamp", C.c_uint64),
]
SIGNATURE = C.c_uint32.from_buffer_copy(b'\nrc:').value
Python equivalent of the Jancy declaration above
And that's all we need to read log records from an .njlog file!
A good design would be to encapsulate the handling of format intrinsics in a wrapper class, which would expose a simple and intuitive interface: open(path) for opening a file, read() for fetching the next log record:
import types
class RecordFile:
def open(self, path):
f = open(path, "rb")
block = f.read(C.sizeof(RecordFileHdr))
hdr = RecordFileHdr.from_buffer_copy(block)
aux_representer_size = hdr.aux_representer_count * 16
if hdr.signature != RecordFileHdr.SIGNATURE or \
hdr.record_offset < C.sizeof(RecordFileHdr) + aux_representer_size
:
f.close()
raise ValueError("invalid log record file header")
self._file.seek(self._hdr.record_offset)
self._f = f
self._hdr = hdr
def read(self):
record_end_offset = self._hdr.record_offset + self._hdr.total_record_size
if self._f.tell() >= record_end_offset:
return None
block = self._f.read(C.sizeof(Record))
record = Record.from_buffer_copy(block)
if record.signature != Record.SIGNATURE:
raise ValueError("invalid log record")
record.data = self._f.read(record.data_size) if record.data_size else []
return recordA parser of .njlog files in Python
Now let's create an instance of this class, open a file, and read records from it one by one:
file = RecordFile()
file.open(path)
while record := file.read():
print(f"Record 0x{record.code:016x}", record.data)The output would look something like this:
Record 0x01d47ff1fc334a18 []
Record 0x01d483f3e69da203 b'ioninja.com:443'
Record 0x01d47ff1fc334a1c b'D}\x07\xd4\x00\x00\x00\x00'
...and so on
Congratulations – you've just enumerated all records in your log file! The decoder above is suitable for any .njlog file generated by any IO Ninja plugin.
But to do something useful with it, we need to know how to cherry-pick and process interesting record codes. So where do we look up all the log record codes and their data formats?
Decoding individual record codes
The user manuals only describe working with IO Ninja plugins from the user's perspective. Implementation details, such as individual log record codes and structures, are not covered there. However, we can once again leverage the fact that IO Ninja scripts are open source.
Let's say you wonder what the very first code 0x01d47ff1fc334a18 in the sample output above means. Open the <IONINJA_DIR>/scripts/ directory and search for 01d47ff1fc334a18:
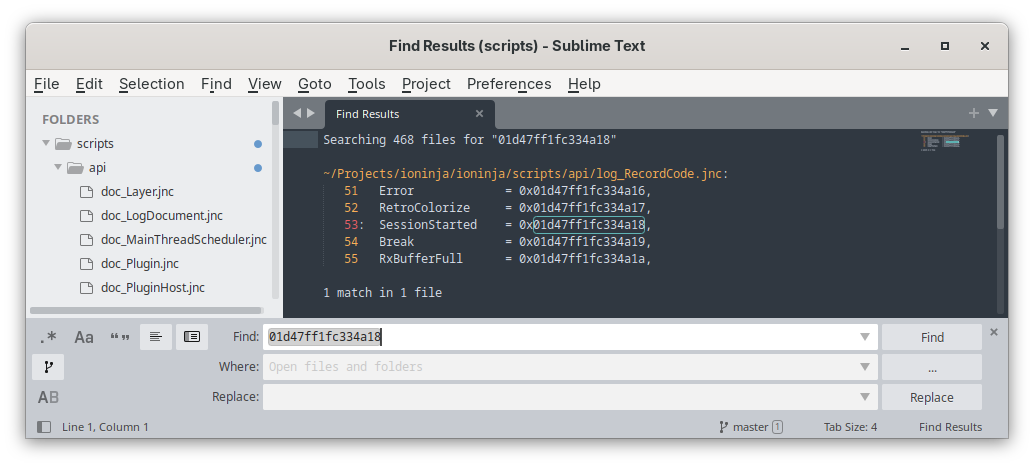
OK, so it's SessionStarted – one of the standard record codes defined in scripts/api/log_RecordCode.jnc:
enum StdRecordCode: uint64_t {
Tx = 0x01d47ff1fc334a10 | PartCodeFlags.Mergeable,
TxSep = 0x01d47ff1fc334a10,
Rx = 0x01d47ff1fc334a11 | PartCodeFlags.Mergeable,
RxSep = 0x01d47ff1fc334a11,
TxRx = 0x01d47ff1fc334a12 | PartCodeFlags.Mergeable,
TxRxSep = 0x01d47ff1fc334a12,
PlainText = 0x01d47ff1fc334a13 | PartCodeFlags.Mergeable,
PlainTextSep = 0x01d47ff1fc334a13,
HyperText = 0x01d47ff1fc334a14 | PartCodeFlags.Mergeable,
HyperTextSep = 0x01d47ff1fc334a14,
Bin = 0x01d47ff1fc334a15 | PartCodeFlags.Mergeable,
BinSep = 0x01d47ff1fc334a15,
Error = 0x01d47ff1fc334a16,
RetroColorize = 0x01d47ff1fc334a17,
SessionStarted = 0x01d47ff1fc334a18,
Break = 0x01d47ff1fc334a19,
RxBufferFull = 0x01d47ff1fc334a1a,
RxBufferFullLossy = 0x01d47ff1fc334a1b,
SyncId = 0x01d47ff1fc334a1c,
Tx9 = 0x01d47ff1fc334a1d | PartCodeFlags.Mergeable,
Tx9Sep = 0x01d47ff1fc334a1d,
Rx9 = 0x01d47ff1fc334a1e | PartCodeFlags.Mergeable,
Rx9Sep = 0x01d47ff1fc334a1e,
TxRx9 = 0x01d47ff1fc334a1f | PartCodeFlags.Mergeable,
TxRx9Sep = 0x01d47ff1fc334a1f,
Bin9 = 0x01d47ff1fc334a20 | PartCodeFlags.Mergeable,
Bin9Sep = 0x01d47ff1fc334a21,
}
Standard record codes are used throughout all plugins
It's probably a good idea to map all these standard record codes to Python – they are shared by all IO Ninja plugins:
import enum
class RecordCodeFlags(enum.IntEnum):
Foldable = 0x8000000000000000,
class PartCodeFlags(enum.IntEnum):
MergeableBackward = 0x2000000000000000,
MergeableForward = 0x4000000000000000,
Mergeable = 0x6000000000000000,
class StdRecordCode(enum.IntEnum):
Tx = 0x01d47ff1fc334a10 | PartCodeFlags.Mergeable,
TxSep = 0x01d47ff1fc334a10,
Rx = 0x01d47ff1fc334a11 | PartCodeFlags.Mergeable,
RxSep = 0x01d47ff1fc334a11,
TxRx = 0x01d47ff1fc334a12 | PartCodeFlags.Mergeable,
TxRxSep = 0x01d47ff1fc334a12,
PlainText = 0x01d47ff1fc334a13 | PartCodeFlags.Mergeable,
PlainTextSep = 0x01d47ff1fc334a13,
HyperText = 0x01d47ff1fc334a14 | PartCodeFlags.Mergeable,
HyperTextSep = 0x01d47ff1fc334a14,
Bin = 0x01d47ff1fc334a15 | PartCodeFlags.Mergeable,
BinSep = 0x01d47ff1fc334a15,
Error = 0x01d47ff1fc334a16,
RetroColorize = 0x01d47ff1fc334a17,
SessionStarted = 0x01d47ff1fc334a18,
Break = 0x01d47ff1fc334a19,
RxBufferFull = 0x01d47ff1fc334a1a,
RxBufferFullLossy = 0x01d47ff1fc334a1b,
SyncId = 0x01d47ff1fc334a1c,
Tx9 = 0x01d47ff1fc334a1d | PartCodeFlags.Mergeable,
Tx9Sep = 0x01d47ff1fc334a1d,
Rx9 = 0x01d47ff1fc334a1e | PartCodeFlags.Mergeable,
Rx9Sep = 0x01d47ff1fc334a1e,
TxRx9 = 0x01d47ff1fc334a1f | PartCodeFlags.Mergeable,
TxRx9Sep = 0x01d47ff1fc334a1f,
Bin9 = 0x01d47ff1fc334a20 | PartCodeFlags.Mergeable,
Bin9Sep = 0x01d47ff1fc334a21,
Python declarations for standard record codes
Searching for the next code 0x01d483f3e69da203 tells us it is SocketLogRecordCode.Resolving, defined in scripts/SocketLog/SocketLogRecordCode.jnc
This time there's some data associated with it. How do we process it? Let's search for SocketLogRecordCode.Resolving:
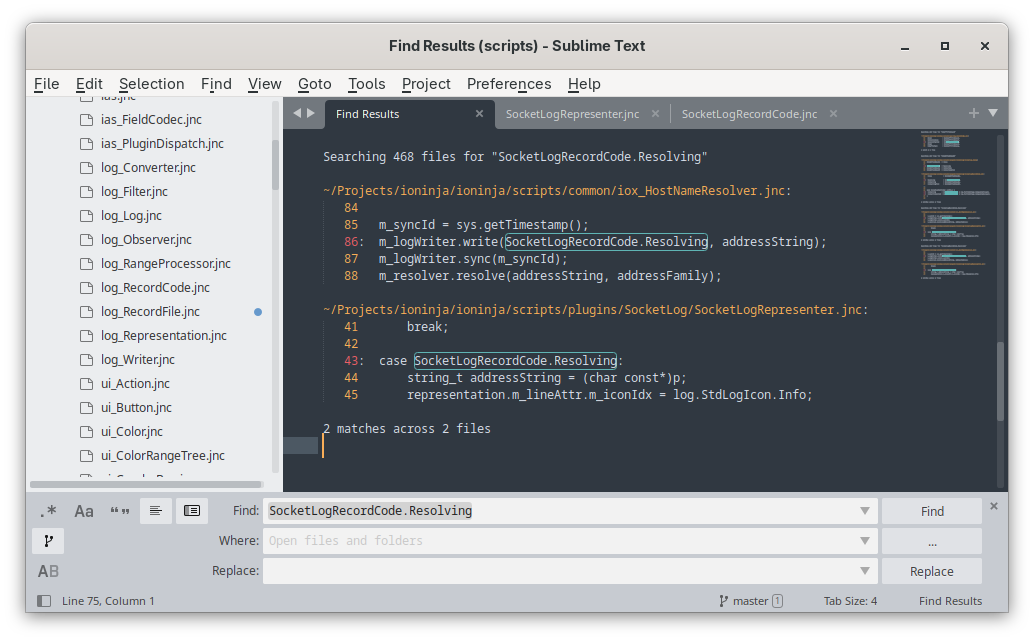
You'll typically find one or more locations that write a particular log record code, and only one that decodes it (inside the corresponding log representer).
log.StdRecordCode.*) as it resides inside the IO Ninja binary.All of the found locations – log writes and representers – can be used to understand the format of data associated with this record code.
In the case above, there's only one log write, and it looks like this:
bool errorcode HostNameResolver.resolve(
string_t addressString,
io.AddressFamily addressFamily
) {
// ...
m_logWriter.write(SocketLogRecordCode.Resolving, addressString);
// ...
}When writing a log record with this code, we add a string (hostname) as its data
So here you go: the data parameter of SocketLogRecordCode.Resolving is a hostname string that we try to resolve to a socket address!
The exact same process can be repeated for all the record codes you encounter in an .njlog file. For log.StdRecordCode.Tx, the associated data holds the transmitted bytes, for log.StdRecordCode.Rx, it's the incoming bytes, for SerialLogRecordCode.BaudRateChanged, it's the new baud rate, and so on.
In the end, your Python log walker would look something like this:
file = RecordFile()
file.open(path)
while record := file.read():
match record.code:
case StdRecordCode.Tx:
# process outbound bytes: record.data
case StdRecordCode.Rx:
# process incoming bytes: record.data
case ModbusLogRecordCode.Packet_rtu_master:
# process Modbus RTU master packet: record.data
case ModbusLogRecordCode.Packet_rtu_slave:
# process Modbus RTU slave packet: record.data
# etcTemplate for the main loop of a record file walker
Conclusion
IO Ninja is scriptable and was designed to be Lego-like and extendable with Jancy scripts. However, many users prefer to implement custom logic in a mainstream language they are more familiar with – such as Python. The most straightforward path toward this goal is to save log record files (.njlog) and process them in your favorite language.
This article explains how to walk .njlog files in Python, find the meaning of particular record codes and their associated data blobs using the official IO Ninja scripts, and import the relevant declarations from Jancy into Python.
Resources
A sample Python project that you can use as a skeleton for your own log walker:
https://github.com/vovkos/python-njlog
GitHub repository with the official IO Ninja scripts:
https://github.com/vovkos/ioninja-scripts
Feel free to leave your comments on the forum.